
Por qué hablamos de machine learning
Cada vez hay más datos: correos, fotos, historiales médicos, transacciones, lecturas de sensores, registros de uso en webs y apps. A mano es imposible revisarlo todo y sacar reglas claras.

La idea central del machine learning es simple:
En vez de programar las reglas a mano, dejamos que un algoritmo aprenda esas reglas a partir de los datos.
El objetivo es siempre el mismo: usar datos pasados para tomar mejores decisiones sobre datos futuros. Ejemplos que ya usamos todos los días:
Filtros de correo basura.
Motores de búsqueda.
Recomendaciones de productos o películas.
Sistemas que ayudan a detectar enfermedades en imágenes médicas.
Tres formas de aprendizaje en machine learning
Casi todo lo que se hace con machine learning cae en tres grupos: supervisado, no supervisado y por refuerzo.
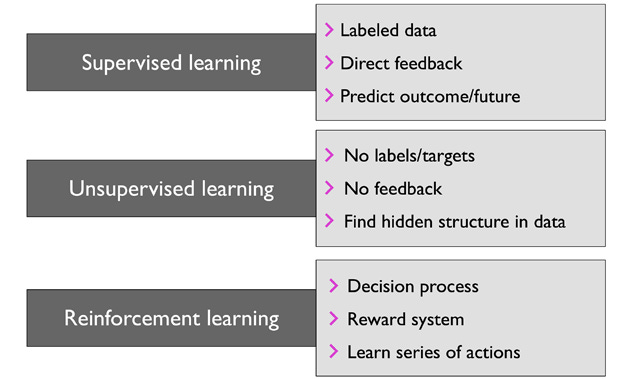
Aprendizaje supervisado
Aquí tenemos ejemplos con “respuesta correcta”. Cada fila del conjunto de datos trae:
entradas (características) → salida (etiqueta u objetivo)
La tarea es aprender la relación entre ambas cosas para poder predecir la salida de ejemplos nuevos.
Hay dos casos típicos.
a) Clasificación
La salida es una clase: una etiqueta de un conjunto finito.
Ejemplos:
Spam o no spam.
Tipo de flor (tres especies distintas).
Reconocimiento de letras escritas a mano.
Imagina un gráfico con puntos de dos colores (clase A y clase B). Cada punto tiene dos características (x₁ y x₂). El modelo aprende una frontera de decisión (una línea o curva) que separa lo mejor posible los puntos de A y los de B. Cuando aparece un punto nuevo, se mira de qué lado de la frontera cae y se le asigna la clase correspondiente.
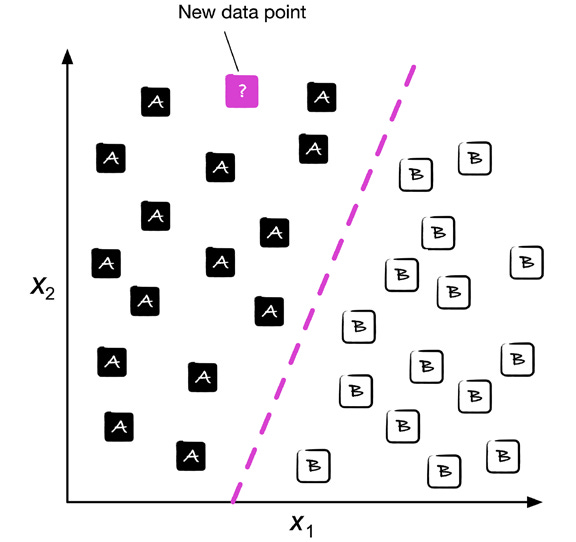
La clasificación puede ser:
Binaria: dos clases (spam / no spam).
Multiclase: muchas clases (letra A, B, C, …).
El modelo solo puede predecir clases que vio en el entrenamiento.
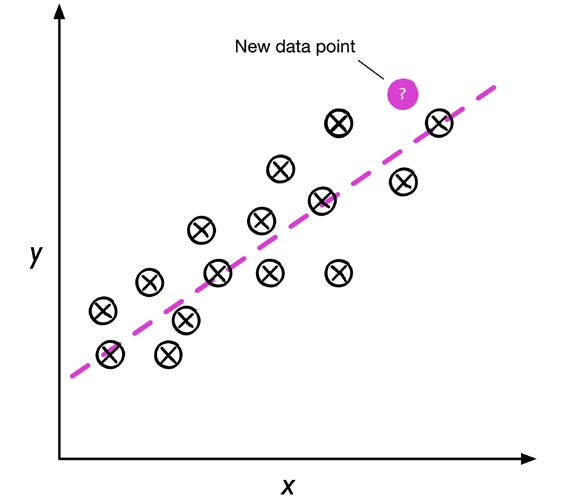
b) Regresión
La salida es un número continuo.
Ejemplo: predecir el puntaje de matemáticas de un examen tipo SAT usando, por ejemplo, las horas de estudio como entrada. Se ajusta una recta a los datos de entrenamiento de forma que quede lo más cerca posible de los puntos. Esa recta permite estimar el puntaje de un estudiante nuevo sabiendo cuántas horas estudió.
En resumen:
Clasificación → clases.
Regresión → números.
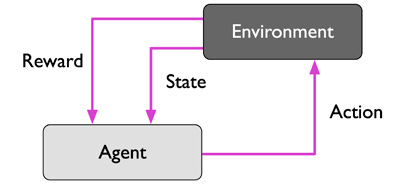
Aprendizaje por refuerzo
Aquí no se aprende a partir de una tabla fija, sino interactuando con un entorno.
Hay un agente que observa el estado del entorno.
El agente toma una acción.
El entorno responde con un nuevo estado y una recompensa (positiva o negativa).
El objetivo del agente es aprender una secuencia de acciones que maximice la recompensa total.
Ejemplo: un programa que juega ajedrez.
El estado es la posición de las piezas en el tablero.
Las acciones son los movimientos permitidos.
La recompensa final es ganar, empatar o perder.
El problema es que la recompensa llega muchas jugadas después y también depende del rival. El agente aprende probando, equivocándose y corrigiendo.
Aprendizaje no supervisado
En este caso no hay etiquetas ni recompensas definidas. Solo tenemos datos y queremos descubrir estructura interna.
Dos tareas muy importantes son:
a) Clustering (agrupamiento)
Se trata de formar grupos de ejemplos parecidos entre sí. Nadie le dice al algoritmo cuántos grupos hay ni cómo se llaman. Solo se le pide que agrupe por similitud de características.
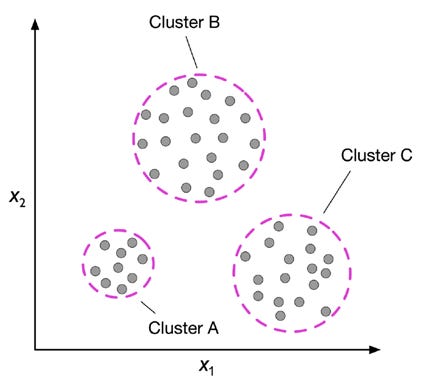
Ejemplo: agrupar clientes según su comportamiento de compra para poder tratarlos de forma distinta después.
En un gráfico con dos características (x₁, x₂) podemos ver cómo los puntos se separan en tres nubes. Cada nube es un grupo.
b) Reducción de dimensionalidad
Cuando cada ejemplo tiene muchas características, trabajar con todas puede ser costoso y ruidoso. La reducción de dimensionalidad intenta comprimir los datos en menos dimensiones, manteniendo la mayor parte de la información.
Sirve para:
Acelerar algoritmos.
Quitar ruido.
Visualizar datos complejos proyectándolos a 2D o 3D.
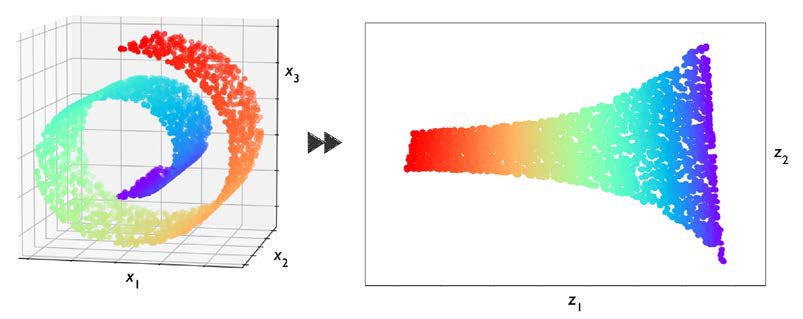
Ejemplo: un “rollo suizo” (una forma enrollada en 3D) que se “desenrolla” y se representa en 2D, conservando la estructura de los puntos.